TF*IDF
La formule TF*IDF permet de déterminer dans quelles proportions certains mots d’un document texte, d'un corps de document ou d’un site web peuvent être évalués par rapport au reste du texte. Cette formule utilise le critère de fréquence et peut être utilisée pour l'optimisation On-Page afin d'augmenter la pertinence d'un site web pour les moteurs de recherche, sans que la densité de mots-clés n'y joue un rôle unique.
Contexte
La formule TF*IDF n'a créé aucune nouvelle règle pour l'optimisation des textes web, mais elle a plutôt permis la redécouverte de la pondération des mots dans un contenu web. Ce type de pondération avait déjà été systématisé par le chercheur en sciences informatiques Hans Peter Luhn[1] en 1957. Avant que le TF*IDF ne soit redécouvert dans le cadre du SEO, la formule a également été utilisée dans les domaines de la linguistique et de la linguistique informatique.
TF
TF est l’abréviation de l’anglais term frenquency (fréquence du terme). Il détermine la fréquence relative d’un mot ou d’une combinaison de mots dans un document. Cette fréquence du terme sera comparée à la survenance de tous les autres mots restants du texte, du document ou du site web analysé. Cette formule utilise un logarithme qui se lit comme suit :
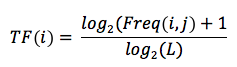
Ce logarithme atteste qu’une augmentation visible du mot-clé dans le texte ne mène pas à une amélioration de sa valeur dans le calcul. Alors que la densité du mot-clé calcule principalement la distribution en pourcentage d’un seul mot dans le texte (en relation avec le nombre total de mots restant), le term frequency prend également en compte la proportion de tous les mots utilisés dans un texte.
IDF
L’IDF calcule le inverse document frequency (la fréquence inverse du document) et complète l’analyse de l’évaluation du mot. Il agit en tant que correctif du TF. L’IDF inclut dans le calcul la fréquence des documents pour un mot précis, autrement dit l’IDF compare le chiffre correspondant à tous les documents connus avec le nombre de textes contenant le mot en question. Le logarithme suivant permet ainsi de "condenser" les résultats :
![]()
En conséquence, l’IDF détermine la pertinence d’un texte en considérant un mot-clé précis.
Les formules multipliées montrent l’évaluation relative du mot d’un texte comparé à tous les documents potentiels qui contiennent le même mot-clé. Afin d’obtenir des résultats utiles, la formule a besoin d’être appliquée à tout mot-clé significatif dans un document texte.
Plus la base de données utilisée pour le calcul du TF*IDF est grande, plus les résultats sont précis.
Intérêt pour le référencement
En termes d’optimisation du référencement, la formule TF*IDF est utile aux utilisateurs quand il s'agit de créer des textes le plus unique possible pour un site Web, une sous-page ou une landing page. Cela permet de viser bons classements dans les SERP pour la recherche de certains mots. Pendant longtemps, la densité des mots-clés était utilisée comme référence pour les textes optimisés. Aujourd'hui, la formule TF-IDF représente une manière beaucoup plus précise d'optimiser ses contenus.
Comme les moteurs de recherche essaient souvent d’interpréter la relation sémantique entre certains mots, il peut être avantageux d’améliorer le contenu de son site web au sein même de sa sémantique. Cela est appelé le Latent Semantic Optimization (analyse sémantique latente).
La formule TF*IDF peut aussi servir dans la détermination des mots-clés qui devraient être idéalement utilisés dans le contenu d’un site web. Avec l’aide d’un outil TF*IDF, les textes peuvent non seulement être optimisés par rapport à un mot-clé précis, mais l’outil met aussi en évidence les mots qui pourraient être inclus directement lors de la création des textes afin de les rendre le plus unique possible.
Limites du TF*IDF
Si les textes ont été optimisés avec les moyens de l’analyse term frequency, les utilisateurs doivent être conscients que tous les éléments du site web ont été inclus dans l’analyse. Cela signifie aussi bien les titres des catégories que les descriptions des produits. Ce type d’optimisation on-page s’adresse donc aux pages possédant une quantité suffisante de contenus. La formule TF*IDF est considérée comme une option peu optimale pour les boutiques en ligne, car ces dernières présentent chaque produit individuellement avec peu de texte. Le TF*IDF doit être vu pour ce qu'il est, c'est-à-dire une formule globale.
En outre, la formule TF*IDF ne prend pas en considération que la recherche de mots peut être cumulative, que des règles de recherche du radical peuvent s’appliquer ou que les textes peuvent de plus en plus faire appel à des synonymes.
Le TF*IDF n'est pas une "arme secrète" qui permet d'optimiser son contenu, mais c'est plutôt un moyen pour créer un contenu aussi unique que possible. L'optimisation des textes n'est par ailleurs qu'un aspect parmi tant d'autres de l'optimisation on-page. Même le meilleur texte écrit selon les standards de la formule TF*IDF ne provoquera pas de meilleurs classements si la page se compose de mauvais backlinks ou n'est pas optimisée pour le mobile.
En conclusion, les agences de rédaction, les auteurs ou les webmasters ne devraient pas uniquement s'orienter à la courbe du TF*IDF. Les résultats de cet outil ne sont que des calculs basés sur des logarithmes. D'autres aspects tels que la tonalités, la vivacité du texte, la structure ou le flux de lecture ne joue aucun rôle dans la pondération des termes. Pour qu'un texte soit vraiment bon, cependant, ces aspects ne doivent pas être négligés lors de l'écriture.
Référence
Liens web
- TF*IDF améliorez votre positionnement sur Google, seoland.fr, ouvert le 31.07.2017
- Quelle approche de l’analyse sémantique pour le référencement?, lightonseo.com, ouvert le 31.07.2017
- Vérificateur de densité de mots clés, consultant-seo.club, ouvert le 18.06.2019